
Yunhe Wang
I am now the head of the Huawei Applied AI lab and also a senior researcher at Huawei Noah's Ark Lab, where I work on deep learning, model compression, and computer vision, etc. Before that, I did my PhD at school of EECS, Peking University, where I was co-advised by Prof. Chao Xu and Prof. Dacheng Tao. I did my bachelors at school of science, Xidian University.
Email / Google Scholar / Zhi Hu / DBLP
News
Recent Projects
Actually, model compression is a kind of technique for developing portable deep neural networks with lower memory and computation costs. I have done several projects in Huawei including some smartphones' applications in 2019 and 2020 (e.g. Mate 30 and Honor V30). Currently, I am leading the AdderNet project, which aims to develop a series of deep learning models using only additions (Discussions on Reddit).
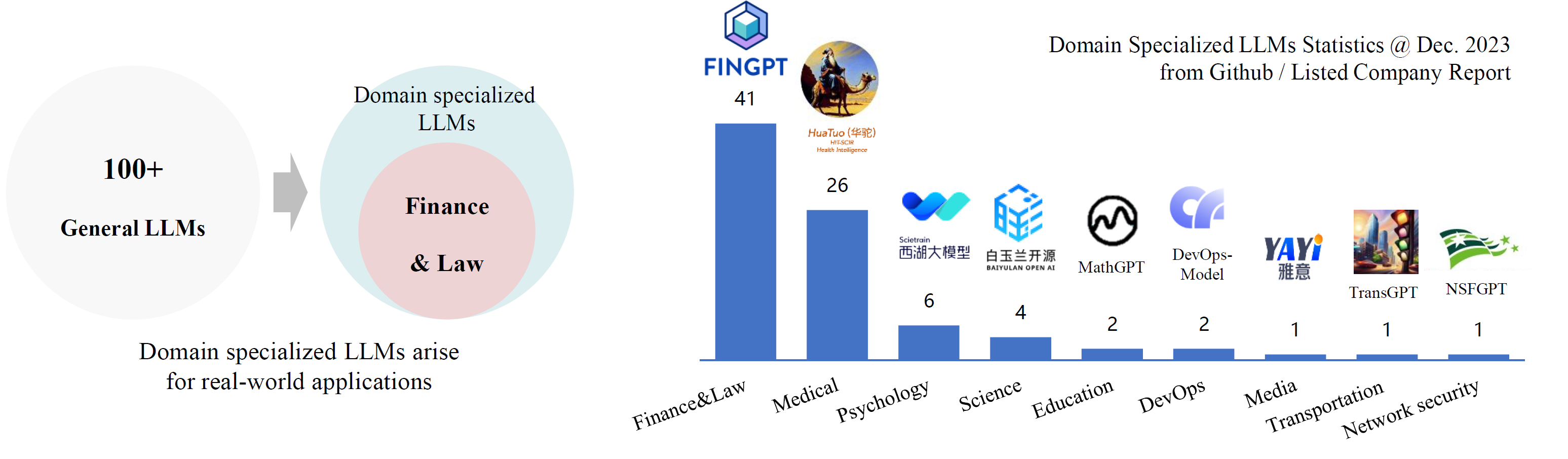
Introducing PanGu-π, a new architecture for Large Language Model. As the world of Large Language Models (LLMs) continues to evolve with larger models and datasets for enhanced performance, the critical aspect of LLM architecture improvement often remains overlooked. PanGu-π addresses this gap by introducing modules that significantly enhance nonlinearity, thereby greatly boosting the model's expressive capabilities. Achieving leading performance and efficiency in both 7B and 1B model scales, PanGu-π is a testament to the power of architectural innovation in LLMs. Further extending its impact, the specialized YunShan model is making waves in high-value domains such as finance and law, showcasing the practical and powerful application of this groundbreaking technology.
Project Page | Paper | Discussion on Zhihu
VanillaNet is remarkable! The concept was born from embracing the "less is more" philosophy in computer vision. It's elegantly designed by avoiding intricate depth and operations, such as self-attention, making it remarkably powerful yet concise. The 6-layer VanillaNet surpasses ResNet-34, and the 13-layer variant achieves about 83% Top-1 accuracy, outpacing the performance of networks with hundreds of layers, and revealing exceptional hardware efficiency advantages.

Project Page | Hardware Implementation
I would like to say, AdderNet is very cool! The initial idea was came up in about 2017 when climbing with some friends at Beijing. By replacing all convolutional layers (except the first and the last layers), we now can obtain comparable performance on ResNet architectures. In addition, to make the story more complete, we recent release the hardware implementation and some quantization methods. The results are quite encouraging, we can reduce both the energy consumption and thecircuit areas significantly without affecting the performance. Now, we are working on more applications to reduce the costs of launching AI algorithms such as low-level vision, detection, and NLP tasks.
Huawei Connect (HC) 2020 | MindSpore Hub
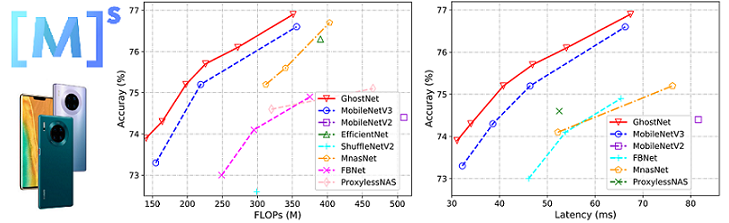
The initial verison of GhostNet was accepted by CVPR 2020, which achieved SOTA performance on ImageNet: 75.7% top1 acc with only 226M FLOPS. In the current version, we release a series computer vision models (e.g. int8 quantization, detection, and larger networks) on MindsSpore 1.0 and Mate 30 Pro (Kirin 990).


Huawei Developer Conference (HDC) 2020 | Online Demo
This project aims to develop a video style transfer system on the Huawei Atlas 200 DK AI developer Kit. The latency of the original model for processing one image is about 630ms. After accelerating it using our method, the lantency now is about 40ms.
Talks
Research
I'm interested in devleoping efficient models for computer vision (e.g. classification, detection, and super-resolution) using pruning, quantization, distilaltion, NAS, etc.
Preprint Papers:
- PanGu-π: Enhancing Language Model Architectures via Nonlinearity Compensation
Yunhe Wang, Hanting Chen, Yehui Tang, Tianyu Guo, Kai Han, Ying Nie, Xutao Wang, Hailin Hu, Zheyuan Bai, Yun Wang, Fangcheng Liu, Zhicheng Liu, Jianyuan Guo, Sinan Zeng, Yinchen Zhang, Qinghua Xu, Qun Liu, Jun Yao, Chao Xu, Dacheng Tao
arXiv 2023.12.xx submitted | paper
Conference Papers:
- Accelerating Sparse Convolution with Column Vector-Wise Sparsity
Yijun Tan, Kai Han, Kang Zhao, Xianzhi Yu, Zidong Du, Yunji Chen, Yunhe Wang, Jun Yao
NeurIPS 2022 | paper - Learning Efficient Vision Transformers via Fine-Grained Manifold Distillation
Zhiwei Hao, Jianyuan Guo, Ding Jia, Kai Han, Yehui Tang, Chao Zhang, Han Hu, Yunhe Wang
NeurIPS 2022 | paper - A Transformer-Based Object Detector with Coarse-Fine Crossing Representations
Zhishan Li, Ying Nie, Kai Han, Jianyuan Guo, Lei Xie, Yunhe Wang
NeurIPS 2022 | paper | MindSpore code - Bridge the Gap Between Architecture Spaces via A Cross-Domain Predictor
Yuqiao Liu, Yehui Tang, Zeqiong Lv, Yunhe Wang, Yanan Sun
NeurIPS 2022 | paper | code | MindSpore code - Random Normalization Aggregation for Adversarial Defense
Minjing Dong, Xinghao Chen, Yunhe Wang, Chang Xu
NeurIPS 2022 | paper | code | MindSpore code - Redistribution of Weights and Activations for AdderNet Quantization
Ying Nie, Kai Han, Haikang Diao, Chuanjian Liu, Enhua Wu, Yunhe Wang
NeurIPS 2022 | paper | MindSpore code - BiMLP: Compact Binary Architectures for Vision Multi-Layer Perceptrons
Yixing Xu, Xinghao Chen, Yunhe Wang
NeurIPS 2022 | paper | MindSpore code | Spotlight - GhostNetV2: Enhance Cheap Operation with Long-Range Attention
Yehui Tang, Kai Han, Jianyuan Guo, Chang Xu, Chao Xu, Yunhe Wang
NeurIPS 2022 | paper | code | Spotlight - Vision GNN: An Image is Worth Graph of Nodes
Kai Han*, Yunhe Wang*, Jianyuan Guo, Yehui Tang, Enhua Wu
NeurIPS 2022 (* equal contribution) | paper | code | MindSpore code - Spatial-Channel Token Distillation for Vision MLPs
Yanxi Li, Xinghao Chen, Minjing Dong, Yehui Tang, Yunhe Wang, Chang Xu
ICML 2022 | paper - Federated Learning with Positive and Unlabeled Data
Xinyang Lin, Hanting Chen, Yixing Xu, Chao Xu, Xiaolin Gui, Yiping Deng, Yunhe Wang
ICML 2022 | paper - Brain-inspired Multilayer Perceptron with Spiking Neurons
Wenshuo Li, Hanting Chen, Jianyuan Guo, Ziyang Zhang, Yunhe Wang
CVPR 2022 | paper | MindSpore code - Source-Free Domain Adaptation via Distribution Estimation
Ning Ding, Yixing Xu, Yehui Tang, Chao Xu, Yunhe Wang, Dacheng Tao
CVPR 2022 | paper - Multimodal Token Fusion for Vision Transformers
Yikai Wang, Xinghao Chen, Lele Cao, Wenbing Huang, Fuchun Sun, Yunhe Wang
CVPR 2022 | paper | code | MindSpore code - An Image Patch is a Wave: Phase-Aware Vision MLP
Yehui Tang, Kai Han, Jianyuan Guo, Chang Xu, Yanxi Li, Chao Xu, Yunhe Wang
CVPR 2022 | paper | code | Oral Presentation - Instance-Aware Dynamic Neural Network Quantization
Zhenhua Liu, Yunhe Wang, Kai Han, Siwei Ma, Wen Gao
CVPR 2022 | paper | code | MindSpore code | Oral Presentation - Hire-MLP: Vision MLP via Hierarchical Rearrangement
Jianyuan Guo, Yehui Tang, Kai Han, Xinghao Chen, Han Wu, Chao Xu, Chang Xu, Yunhe Wang
CVPR 2022 | paper - CMT: Convolutional Neural Networks Meet Vision Transformers
Jianyuan Guo, Kai Han, Han Wu, Yehui Tang, Xinghao Chen, Yunhe Wang, Chang Xu
CVPR 2022 | paper - Patch Slimming for Efficient Vision Transformers
Yehui Tang, Kai Han, Yunhe Wang, Chang Xu, Jianyuan Guo, Chao Xu, Dacheng Tao
CVPR 2022 | paper - Transformer in Transformer
Kai Han, An Xiao, Enhua Wu, Jianyuan Guo, Chunjing Xu, Yunhe Wang
NeurIPS 2021 | paper | code | MindSpore code - Learning Frequency Domain Approximation for Binary Neural Networks
Yixing Xu, Kai Han, Chang Xu, Yehui Tang, Chunjing Xu, Yunhe Wang
NeurIPS 2021 | paper | Oral Presentation - Dynamic Resolution Network
Mingjian Zhu*, Kai Han*, Enhua Wu, Qiulin Zhang, Ying Nie, Zhenzhong Lan, Yunhe Wang
NeurIPS 2021 (* equal contribution) | paper - Post-Training Quantization for Vision Transformer
Zhenhua Liu, Yunhe Wang, Kai Han, Wei Zhang, Siwei Ma, Wen Gao
NeurIPS 2021 | paper - Augmented Shortcuts for Vision Transformers
Yehui Tang, Kai Han, Chang Xu, An Xiao, Yiping Deng, Chao Xu, Yunhe Wang
NeurIPS 2021 | paper - Adder Attention for Vision Transformer
Han Shu*, Jiahao Wang*, Hanting Chen, Lin Li, Yujiu Yang, Yunhe Wang
NeurIPS 2021 (* equal contribution) | paper - Towards Stable and Robust Addernets
Minjing Dong, Yunhe Wang, Xinghao Chen, Chang Xu
NeurIPS 2021 | paper - Handling Long-Tailed Feature Distribution in Addernets
Minjing Dong, Yunhe Wang, Xinghao Chen, Chang Xu
NeurIPS 2021 | paper - Neural Architecture Dilation for Adversarial Robustness
Yanxi Li, Zhaohui Yang, Yunhe Wang, Chang Xu
NeurIPS 2021 | paper - An Empirical Study of Adder Neural Networks for Object Detection
Xinghao Chen, Chang Xu, Minjing Dong, Chunjing Xu, Yunhe Wang
NeurIPS 2021 | paper - Learning Frequency-Aware Dynamic Network for Efficient Super-Resolution
Wenbin Xie, Dehua Song, Chang Xu, Chunjing Xu, Hui Zhang, Yunhe Wang
ICCV 2021 | paper - Winograd Algorithm for AdderNet
Wenshuo Li, Hanting Chen, Mingqiang Huang, Xinghao Chen, Chunjing Xu, Yunhe Wang
ICML 2021 | paper - Distilling Object Detectors via Decoupled Features
Jianyuan Guo, Kai Han, Yunhe Wang, Wei Zhang, Chunjing Xu, Chang Xu
CVPR 2021 | paper - HourNAS: Extremely Fast Neural Architecture Search Through an Hourglass Lens
Zhaohui Yang, Yunhe Wang, Xinghao Chen, Jianyuan Guo, Wei Zhang,
Chao Xu, Chunjing Xu, Dacheng Tao, Chang Xu
CVPR 2021 | paper | MindSpore code - Manifold Regularized Dynamic Network Pruning
Yehui Tang, Yunhe Wang, Yixing Xu, Yiping Deng, Chao Xu, Dacheng Tao, Chang Xu
CVPR 2021 | paper | MindSpore code - Learning Student Networks in the Wild
Hanting Chen, Tianyu Guo, Chang Xu, Wenshuo Li, Chunjing Xu, Chao Xu, Yunhe Wang
CVPR 2021 | paper - AdderSR: Towards Energy Efficient Image Super-Resolution
Dehua Song*, Yunhe Wang*, Hanting Chen, Chang Xu, Chunjing Xu, Dacheng Tao
CVPR 2021 (* equal contribution) | paper | code | Oral Presentation - ReNAS: Relativistic Evaluation of Neural Architecture Search
Yixing Xu, Yunhe Wang, Kai Han, Yehui Tang, Shangling Jui, Chunjing Xu, Chang Xu
CVPR 2021 | paper | MindSpore code | Oral Presentation - Pre-Trained Image Processing Transformer
Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu,
Siwei Ma, Chunjing Xu, Chao Xu, Wen Gao
CVPR 2021 | paper | MindSpore code | Pytorch code - Data-Free Knowledge Distillation For Image Super-Resolution
Yiman Zhang, Hanting Chen, Xinghao Chen, Yiping Deng, Chunjing Xu, Yunhe Wang
CVPR 2021 | paper - Positive-Unlabeled Data Purification in the Wild for Object Detection
Jianyuan Guo, Kai Han, Han Wu, Xinghao Chen, Chao Zhang, Chunjing Xu, Chang Xu, Yunhe Wang
CVPR 2021 | paper - One-shot Graph Neural Architecture Search with Dynamic Search Space
Yanxi Li, Zean Wen, Yunhe Wang, Chang Xu
AAAI 2021 paper - Adversarial Robustness through Disentangled Representations
Shuo Yang, Tianyu Guo, Yunhe Wang, Chang Xu
AAAI 2021 paper - Kernel Based Progressive Distillation for Adder Neural Networks
Yixing Xu, Chang Xu, Xinghao Chen, Wei Zhang, Chunjing Xu, Yunhe Wang
NeurIPS 2020 | paper | code | Spotlight - Model Rubik's Cube: Twisting Resolution, Depth and Width for TinyNets
Kai Han*, Yunhe Wang*, Qiulin Zhang, Wei Zhang, Chunjing Xu, Tong Zhang
NeurIPS 2020 (* equal contribution) | paper | code - Residual Distillation: Towards Portable Deep Neural Networks without Shortcuts
Guilin Li*, Junlei Zhang*, Yunhe Wang, Chuanjian Liu, Matthias Tan, Yunfeng Lin,
Wei Zhang, Jiashi Feng, Tong Zhang
NeurIPS 2020 (* equal contribution) | paper | code - Searching for Low-Bit Weights in Quantized Neural Networks
Zhaohui Yang, Yunhe Wang, Kai Han, Chunjing Xu, Chao Xu, Dacheng Tao, Chang Xu
NeurIPS 2020 | paper | code - SCOP: Scientific Control for Reliable Neural Network Pruning
Yehui Tang, Yunhe Wang, Yixing Xu, Dacheng Tao, Chunjing Xu, Chao Xu, Chang Xu
NeurIPS 2020 | paper | code - Adapting Neural Architectures Between Domains
Yanxi Li, Zhaohui Yang, Yunhe Wang, Chang Xu
NeurIPS 2020 | paper | code - Discernible Image Compression
Zhaohui Yang, Yunhe Wang, Chang Xu, Peng Du, Chao Xu, Chunjing Xu, Qi Tian
ACM MM 2020 | paper - Optical Flow Distillation: Towards Efficient and Stable Video Style Transfer
Xinghao Chen*, Yiman Zhang*, Yunhe Wang, Han Shu, Chunjing Xu, Chang Xu
ECCV 2020 (* equal contribution) | paper | code - Learning Binary Neurons with Noisy Supervision
Kai Han, Yunhe Wang, Yixing Xu, Chunjing Xu, Enhua Wu, Chang Xu
ICML 2020 | paper - Neural Architecture Search in a Proxy Validation Loss Landscape
Yanxi Li, Minjing Dong, Yunhe Wang, Chang Xu
ICML 2020 | paper - On Positive-Unlabeled Classification in GAN
Tianyu Guo, Chang Xu, Jiajun Huang, Yunhe Wang, Boxin Shi, Chao Xu, Dacheng Tao
CVPR 2020 | paper - CARS: Continuous Evolution for Efficient Neural Architecture Search
Zhaohui Yang, Yunhe Wang, Xinghao Chen, Boxin Shi, Chao Xu, Chunjing Xu, Qi Tian, Chang Xu
CVPR 2020 | paper | code - AdderNet: Do We Really Need Multiplications in Deep Learning?
Hanting Chen*, Yunhe Wang*, Chunjing Xu, Boxin Shi, Chao Xu, Qi Tian, Chang Xu
CVPR 2020 (* equal contribution) | paper | code | Oral Presentation
- A Semi-Supervised Assessor of Neural Architectures
Yehui Tang, Yunhe Wang, Yixing Xu, Hanting Chen, Boxin Shi, Chao Xu, Chunjing Xu, Qi Tian, Chang Xu
CVPR 2020 | paper - Hit-Detector: Hierarchical Trinity Architecture Search for Object Detection
Jianyuan Guo, Kai Han, Yunhe Wang, Chao Zhang, Zhaohui Yang, Han Wu, Xinghao Chen, Chang Xu
CVPR 2020 | paper | code - Frequency Domain Compact 3D Convolutional Neural Networks
Hanting Chen, Yunhe Wang, Han Shu, Yehui Tang, Chunjing Xu, Boxin Shi, Chao Xu, Qi Tian, Chang Xu
CVPR 2020 | paper - GhostNet: More Features from Cheap Operations
Kai Han, Yunhe Wang, Qi Tian, Jianyuan Guo, Chunjing Xu, Chang Xu
CVPR 2020 | paper | code - Beyond Dropout: Feature Map Distortion to Regularize Deep Neural Networks
Yehui Tang, Yunhe Wang, Yixing Xu, Boxin Shi, Chao Xu, Chunjing Xu, Chang Xu
AAAI 2020 | paper | code - DropNAS: Grouped Operation Dropout for Differentiable Architecture Search
Weijun Hong, Guilin Li, Weinan Zhang, Ruiming Tang, Yunhe Wang, Zhenguo Li, Yong Yu
IJCAI 2020 | paper - Distilling Portable Generative Adversarial Networks for Image Translation
Hanting Chen, Yunhe Wang, Han Shu, Changyuan Wen, Chunjing Xu, Boxin Shi, Chao Xu, Chang Xu
AAAI 2020 | paper - Efficient Residual Dense Block Search for Image Super-Resolution
Dehua Song, Chang Xu, Xu Jia, Yiyi Chen, Chunjing Xu, Yunhe Wang
AAAI, 2020 | paper | code - Positive-Unlabeled Compression on the Cloud
Yixing Xu, Yunhe Wang, Hanting Chen, Kai Han, Chunjing Xu, Dacheng Tao, Chang Xu
NeurIPS 2019 | paper | code | supplement - Data-Free Learning of Student Networks
Hanting Chen,Yunhe Wang, Chang Xu, Zhaohui Yang, Chuanjian Liu, Boxin Shi,
Chunjing Xu, Chao Xu, Qi Tian
ICCV 2019 | paper | code - Co-Evolutionary Compression for Unpaired Image Translation
Han Shu, Yunhe Wang, Xu Jia, Kai Han, Hanting Chen, Chunjing Xu, Qi Tian, Chang Xu
ICCV 2019 | paper | code - LegoNet: Efficient Convolutional Neural Networks with Lego Filters
Zhaohui Yang, Yunhe Wang, Hanting Chen, Chuanjian Liu, Boxin Shi, Chao Xu, Chunjing Xu, Chang Xu
ICML 2019 | paper | code - Learning Instance-wise Sparsity for Accelerating Deep Models
Chuanjian Liu, Yunhe Wang, Kai Han, Chunjing Xu, Chang Xu
IJCAI 2019 | paper - Attribute Aware Pooling for Pedestrian Attribute Recognition
Kai Han, Yunhe Wang, Han Shu, Chuanjian Liu, Chunjing Xu, Chang Xu
IJCAI 2019 | paper - Crafting Efficient Neural Graph of Large Entropy
Minjing Dong, Hanting Chen, Yunhe Wang, Chang Xu
IJCAI 2019 | paper - Low Resolution Visual Recognition via Deep Feature Distillation
Mingjian Zhu, Kai Han, Chao Zhang, Jinlong Lin, Yunhe Wang
ICASSP 2019 | paper - Learning Versatile Filters for Efficient Convolutional Neural Networks
Yunhe Wang, Chang Xu, Chunjing Xu, Chao Xu, Dacheng Tao
NeurIPS 2018 | paper | code | supplement - Towards Evolutionary Compression
Yunhe Wang, Chang Xu, Jiayan Qiu, Chao Xu, Dacheng Tao
SIGKDD 2018 | paper - Autoencoder Inspired Unsupervised Feature Selection
Kai Han, Yunhe Wang, Chao Zhang, Chao Li, Chao Xu
ICASSP 2018 | paper | code - Adversarial Learning of Portable Student Networks
Yunhe Wang, Chang Xu, Chao Xu, Dacheng Tao
AAAI 2018 | paper - Beyond Filters: Compact Feature Map for Portable Deep Model
Yunhe Wang, Chang Xu, Chao Xu, Dacheng Tao
ICML 2017 | paper | code | supplement - Beyond RPCA: Flattening Complex Noise in the Frequency Domain
Yunhe Wang, Chang Xu, Chao Xu, Dacheng Tao
AAAI 2017 | paper - Privileged Multi-Label Learning
Shan You, Chang Xu, Yunhe Wang, Chao Xu, Dacheng Tao
IJCAI 2017 | paper - CNNpack: Packing Convolutional Neural Networks in the Frequency Domain
Yunhe Wang, Chang Xu, Shan You, Chao Xu, Dacheng Tao
NeurIPS 2016 | paper | supplement
Journal Papers:
- Neural Architecture Search via Proxy Validation
Yanxi Li, Minjing Dong, Yunhe Wang, Chang Xu
IEEE TPAMI 2022 | paper - Local Means Binary Networks for Image Super-Resolution
Keyu Li, Nannan Wang, Jingwei Xin, Xinrui Jiang, Jie Li, Xinbo Gao, Kai Han, Yunhe Wang
IEEE TNNLS 2022 | paper - GhostNets on Heterogeneous Devices via Cheap Operations
Kai Han, Yunhe Wang, Chang Xu, Jianyuan Guo, Chunjing Xu, Enhua Wu, Qi Tian
IJCV 2022 | paper | code - A Survey on Visual Transformer
Kai Han, Yunhe Wang, Hanting Chen, Xinghao Chen, Jianyuan Guo, Zhenhua Liu, Yehui Tang, An Xiao, Chunjing Xu, Yixing Xu, Zhaohui Yang, Yiman Zhang, Dacheng Tao
IEEE TPAMI 2022 | paper - Learning Versatile Convolution Filters for Efficient Visual Recognition
Kai Han*, Yunhe Wang*, Chang Xu, Chunjing Xu, Enhua Wu, Dacheng Tao
IEEE TPAMI 2021 (* equal contribution) | paper | code - Adversarial Recurrent Time Series Imputation
Shuo Yang, Minjing Dong, Yunhe Wang, Chang Xu
IEEE TNNLS 2020 |paper - Learning Student Networks via Feature Embedding
Hanting Chen, Yunhe Wang, Chang Xu, Chao Xu, Dacheng Tao
IEEE TNNLS 2020 | paper - Packing Convolutional Neural Networks in the Frequency Domain
Yunhe Wang, Chang Xu, Chao Xu, Dacheng Tao
IEEE TPAMI 2018 | paper - DCT Regularized Extreme Visual Recovery
Yunhe Wang, Chang Xu, Shan You, Chao Xu, Dacheng Tao
IEEE TIP 2017 | paper - DCT Inspired Feature Transform for Image Retrieval and Reconstruction
Yunhe Wang, Miaojing Shi, Shan You, Chao Xu
IEEE TIP 2016 | paper
Workshop Papers:
- PyramidTNT: Improved Transformer-in-Transformer Baselines with Pyramid Architecture
Kai Han, Jianyuan Guo, Yehui Tang, Yunhe Wang
CVPR Workshop 2022 | paper | code - Network Amplification with Efficient MACs Allocation
Chuanjian Liu, Kai Han, An Xiao, Ying Nie, Wei Zhang, Yunhe Wang
CVPR Workshop 2022 | paper - Searching for Energy-Efficient Hybrid Adder-Convolution Neural Networks
Wenshuo Li, Xinghao Chen, Jinyu Bai, Xuefei Ning, Yunhe Wang
CVPR Workshop 2022 | paper - Searching for Accurate Binary Neural Architectures
Mingzhu Shen, Kai Han, Chunjing Xu, Yunhe Wang
ICCV Neural Architectures Workshop 2019 | paper
Services
Awards
Note: If you use this template, please remove the following code or replace it with your own counter!.
No.
 Visitor Since Feb 2023. Powered by w3.css
Visitor Since Feb 2023. Powered by w3.css